Winning the Generative Search Race
A guide to AEO and GEO for fashion and luxury brands
How AI-mediated discovery is changing what shoppers find, what they buy, and what brands need to do about it. Anchored in a proprietary Measmerize study of 60,000 reviews across 60 fashion and luxury brands.
Executive summary
Search is no longer a list of links. For a growing share of shoppers, search is a direct answer generated by an AI engine: ChatGPT, Perplexity, Google AI Overviews, Claude, Gemini, or Grok. Research by The Boston Consulting Group finds that 22% of GenAI users have already used these tools to research brands and products to purchase, up from 19% in late 2024.1 LLM referral traffic in fashion and sport grew roughly twentyfold year on year in 2025.2 The trajectory points to potentially up to five percent of total web traffic flowing through LLMs within twelve months.
The discipline that wins inside that answer is Answer Engine Optimisation (AEO) or, in its broader form, Generative Engine Optimisation (GEO). On-site work — schema, FAQs, long-form content, technical hygiene — is necessary but not sufficient. The decisive competition happens off-site. Only 38% of pages cited in AI Overviews appear in Google's top ten organic results.3 96% of fashion citations during the most recent holiday cycle on Gemini went to non-retailers.4 Large language models systematically over-index user-generated content (UGC), editorial coverage, and forum discussion to minimise hallucination risk.
That presents a specific problem for fashion and luxury. The user review ecosystem (Trustpilot, retailer reviews, Reddit, YouTube transcripts, TikTok, X, …) is the same off-site graph many fashion brands have historically been least comfortable governing. To understand what AI engines are actually being told about fashion brands, Measmerize built a curated dataset of 60,000 reviews: 1,000 from each of 60 brands across mass-market, mid-market, premium, and luxury categories. The reviews were clustered into nine macro topics and analysed for sentiment.
Size and Fit is the single largest topic in the dataset. It accounts for 30% of all reviews, and 60% of those reviews are negative. In apparel, Size and Fit alone draws 45% of all reviews. Quality and Construction sits behind it at 25% of reviews overall, also 60% negative. Customer Service and Returns drives the negative discourse in luxury, where 35% of luxury footwear reviews are negative on returns and only 2% are positive. The brightest spot in the conversation is Style and Design: 83% of reviews on style across the industry are positive.
The implication for AI search visibility is sharp. The biggest single signal LLMs are picking up about fashion brands today is dissatisfaction with sizing and fit. Fixing that signal — through better size charts, AI-driven size recommendation, body measurement tooling, and virtual try-on — is the highest-return AEO investment a fashion brand can make. The work needed in luxury extends into quality storytelling and a re-engineered returns experience. Across the board, it requires actively governing the off-site conversation rather than ignoring it.
This white paper sets out the shift from SEO to AEO and GEO, explains what fashion and luxury brands can and cannot control, presents the Measmerize study in detail, and translates the findings into a four-priority action plan.
From clicks to answers: why AEO and GEO matter now
What is AEO, and how is it different from SEO?
Something fundamental has shifted in how people find products. For two decades, search was a list of ten blue links and a competition to rank inside that list. Search engine optimisation grew up around that competition: keyword research, on-page hygiene, backlinks, technical crawlability. Win the rank, win the traffic, win the sale.
That model is being replaced. When a shopper asks ChatGPT, Perplexity, Google AI Overviews, Claude, or Gemini for the best wool coats under €800 with a slim cut for a tall man, they do not get ten links. They get a recommendation. The links sit beneath the answer, or do not appear at all.
Answer Engine Optimisation, usually abbreviated AEO, and Generative Engine Optimisation, abbreviated GEO, are the disciplines that have emerged to compete inside that answer. The two terms are often used interchangeably. AEO emphasises being the source the model quotes when it answers a question. GEO emphasises shaping the generative response itself across every surface where AI now writes the verdict on a brand. Whichever label you prefer, the underlying shift is the same. The unit of competition is no longer the page rank. It is the citation inside a generated response.
How big is the shift, and is it actually happening yet?
It is happening, and it is happening fast. Research by The Boston Consulting Group (BCG Global Consumer Radar Survey, February 2025), drawing on first-party traffic data from a sample of twenty European fashion, sport, luxury, and specialty retailers, captures the moment with unusual clarity. Across eight major markets, 48% of consumers say they are excited about how generative AI can help brands deliver better products and services. 22% of GenAI users have already used these tools to research brands and products to purchase, up from 19% in September 2024.5
The use cases line up directly with the decisions that determine which brand the shopper puts in the basket. 69% use GenAI to compare product features. 65% use it to learn more about a brand. 52% search for deals and promotions. 49% discover new brands they had not heard of before. 49% do a price comparison. 46% gather or summarise customer reviews.5 None of those behaviours are peripheral. Each one used to be a Google search. Now they are a conversation with an AI engine.
The traffic data corroborates the consumer surveys. Across the same sample, LLM referral traffic grew roughly twentyfold year on year in fashion and sport, twelvefold in luxury, and sevenfold in specialty retail through 2025. Across the same period, organic Google traffic was flat to declining in every category. LLM referrals are still under one percent of total traffic today, but the trajectory points to roughly five percent within twelve months: twice the share of display traffic and half the share of social. Google's own AI Mode and AI Overviews already appear in more than twenty percent of search results pages, often suppressing the click on the underlying links.
How does the ranking logic actually change? AEO vs SEO
The shift from SEO to AEO and GEO is not a tuning exercise. It is a different game with a different scoreboard. The table below maps the four dimensions where the two paradigms diverge.
Table 1. SEO vs AEO and GEO: the four shifts
 Source: The Boston Consulting Group, May 2026.
Source: The Boston Consulting Group, May 2026.
The right-hand column does not just reshuffle the tasks. It changes which team owns the result. SEO was a marketing function. AEO sits at the intersection of marketing, digital, PR, customer experience, and product. The brand most ready for the new paradigm is the one whose departments can actually coordinate on the off-site signal that LLMs read.
On-site AEO: what you can control
On-site AEO covers everything a brand can change inside the four walls of its own website. It splits into two workstreams that should run in parallel: an editorial workstream that improves what the site says, and a technical workstream that improves how the site can be read.
What on-site content makes a brand more citable by AI?
Large language models reward content that answers a clear question with credible specificity. Five practices matter most, and a sixth, structured data, sits underneath all of them.
-
Authoritative long-form editorials and guides. A product detail page is not enough. Buying guides, sizing explainers, material primers, and category overviews give models the substance they need to cite. The pages should target the high-volume prompts shoppers actually ask. Examples drawn from live keyword research:6 how does cashmere quality vary by grade, what is the difference between a peacoat and an overcoat, how should a luxury sneaker that runs narrow be sized, when does an Italian-made leather bag justify its premium. Each of those is a question a real shopper types into a real AI engine today.
-
FAQ and Q&A content formats. Question-and-answer structure is, in effect, native to how LLMs construct responses. Branded FAQs, product FAQs, and category FAQs make the model's job easier. The brand that writes the cleanest answer to a question often becomes the source of the model's answer to that question, and the link the model surfaces if it chooses to cite anything at all.
-
Clear header hierarchy and descriptive metadata. Page titles, H1s, H2s, and meta descriptions are the semantic scaffolding the model uses to understand the page. Title-case headings stuffed with keywords are an artefact of the old game. Sentence-case headings that mirror the way a person actually phrases a question are the new standard. The question-shaped headings in this paper are a small example.
-
Brand entity signals. AI engines maintain an internal model of who you are, what you sell, who your customers are, and what you stand for. Structured data (schema markup), consistent brand descriptions across pages, well-defined product schemas, and clear entity definitions all sharpen that internal model. Inconsistency between what the homepage says, what the about page says, and what the product page says is what produces hallucinations.
-
Content that answers the question directly. Open the paragraph with the answer. Use the rest to support it. Bury the answer behind throat-clearing and the model is more likely to quote a competitor who got to the point. Models look for clean, declarative sentences that can be lifted into a response with the lowest possible risk of misquoting the source.
What on-site technical work supports AEO?
The technical layer is less glamorous but no less important. It covers updated XML sitemaps, removal of duplicate page titles and meta descriptions, faster page loads, broken-link hygiene, and the elimination of duplicate product pages that confuse both Google and AI engines about which URL is canonical.
One technical priority deserves particular attention. A surprising amount of fashion and luxury site content still relies on JavaScript-only rendering. Many crawler agents that power LLM indexing do not execute JavaScript. Anything not present in the raw HTML may not be readable by the model. Converting JavaScript-rendered content into server-rendered or pre-rendered HTML can, in some cases, single-handedly bring a brand back into the citation graph.
Done well, on-site AEO is necessary. It is also the easy part. The competitive battle has moved off-site.
Off-site AEO: where the battle is actually won
If on-site AEO is the work you can directly control, off-site AEO is the work you can only influence. The data is clear that off-site is where the real differentiation happens.
Why is off-site AEO so decisive?
Two recent findings on analysis of LLM citation behaviour truly crystallise the asymmetry.
The first. Only 38% of the pages cited in AI Overviews appear in Google's top ten organic results. Out of the 62% that don't appear in the top 10, half (31%) of cited URLs rank beyond position 100, or do not appear in traditional search indexes at all.7 The sources LLMs reach for are systematically different from the sources Google's classical algorithm rewards. Optimising for SEO and assuming AEO will follow is a category error.
The second. When Gemini was asked product questions during the most recent holiday cycle, only 4% of citations went to direct retailers. 96% went to non-retailer sources: review platforms, forums, editorial sites, video transcripts, community discussion.8 Models over-index user-generated and editorial content specifically to minimise hallucination risk. The model would rather cite a Reddit thread containing a hundred specific anecdotes than a product description page written by the brand itself.
This is the off-site paradox. Carefully optimising a brand's own site ends up yielding decreasing returns in terms of new information it adds to what the model already infers about brand-controlled content. Models reach outward for the signal they cannot extract from a brand-controlled corpus. A brand can have a flawless site, perfectly structured schema, and zero technical debt. It can still be invisible inside ChatGPT, Perplexity, and Gemini if the broader digital ecosystem is silent about it, confused about it, or worse, hostile to it.
What does off-site AEO actually require?
It requires governing what is said about the brand on platforms the brand does not own. Reviews on Trustpilot and retailer portals. Threads on Reddit. Video reviews on YouTube. Visual boards on Pinterest. Editorial coverage in Vogue, GQ, Highsnobiety, Business of Fashion, and category-specific verticals. Discussion on X (formerly Twitter) and on TikTok. Comparison articles and product round-ups. Each of these is a node in the citation graph that LLMs consult. Each one shapes the answer the model gives when a shopper asks about your brand.
Some of that work is influence by hospitality: helping the right journalists tell the right story. Some of it is influence by responsiveness: engaging with the review ecosystem rather than ignoring it. Some of it is influence by product: making the underlying experience worth the conversation. A good portion of this sits outside the brand's owned channels, and all of it is now disproportionately weighted by the engines deciding what to recommend.
That work is harder. It is also where the competitive separation is opening up. The data on which sources LLMs actually quote sharpens the picture considerably.
What sources do AI algorithms actually use?
The five major consumer-facing LLMs (ChatGPT, Claude, Gemini, Perplexity, and Grok) do not share a single index. Each pulls from its own preferred sources, and the differences are larger than most marketing teams assume. The citation landscape as of Q1 2026, compiled by Measmerize from Similarweb, Tinuiti/Profound, Peec AI, BrightEdge, Ahrefs Brand Radar, the Semrush AI Visibility Index, SE Ranking, and Conductor benchmark data, reveals five patterns that matter for fashion.9
Which sources dominate generic queries?
The table below shows the share of total citations captured by the top five sources on each engine for generic queries (anything that is not category-specific). Cells are paired: the source name above, the share of citations on that engine below.
Table 2. Top five citation sources by LLM engine, generic queries (2026)
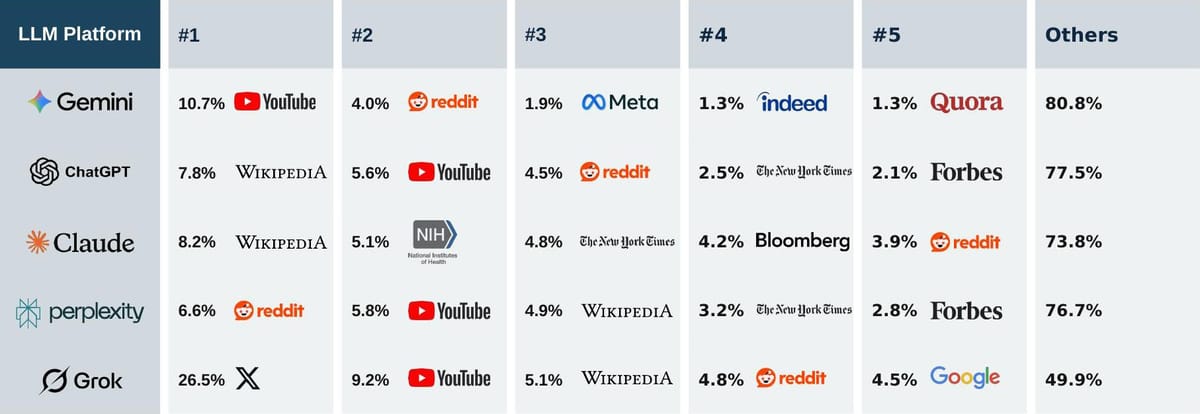 Five patterns are worth pulling out of that table.
Five patterns are worth pulling out of that table.
YouTube is the most under-appreciated cross-platform citation source. It ranks first for Gemini (10.7% on visually anchored queries), in the top two for ChatGPT, Perplexity and Grok. It is the most reliable cross-platform asset class in the dataset.
Reddit's role in LLM visibility is well documented, and indeed it appears in the top 5 of sources for all 5 main LLMs. ChatGPT throttled Reddit citations in late 2025 but still present in the top 5.10 Along with Wikipedia, it is, in effect, the bridge node of the citation graph.
Citation ecosystems are violently model-specific. There is an incredibly long tail of "other" sources for all models. Optimising for one model does not automatically deliver visibility on another. A multi-engine AEO programme needs to be designed engine by engine.
There is a stark editorial-versus-social split. Claude leans hardest into editorial sources (22.3% editorial concentration in its top four). Grok leans hardest into social, with X.com alone delivering 26.5% of its top citations for generic queries. ChatGPT and Gemini sit somewhere between, with their own balances of editorial, social, and visual sources.
Multimodal sources outperform text-only on the visually-led models. YouTube, Pinterest, and Instagram all appear in the top citation sets of models with strong multimodal retrieval. They are essentially invisible on text-first models.
What changes for fashion-specific queries?
Fashion, as is often the case, is different. Everything tilts further toward editorial, social, and user-generated content. The same five engines look meaningfully different when the query is a fashion B2C query.
Table 3. Top five citation sources by LLM engine, fashion B2C queries (2026)
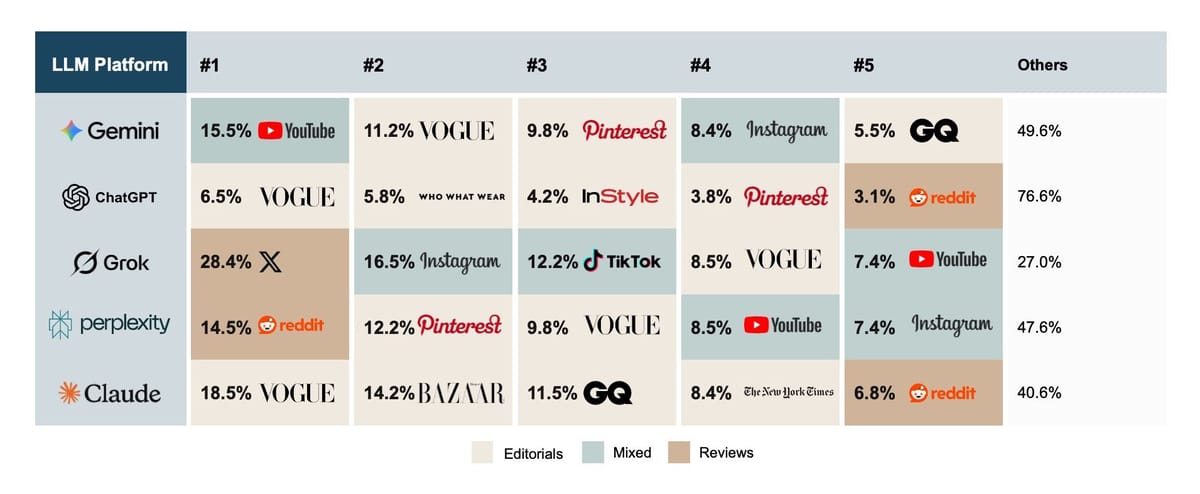 Three sharper observations sit underneath that table.
Three sharper observations sit underneath that table.
Editorial authority compounds across engines. Four of the top five fashion sources for ChatGPT are editorial. Claude (even though currently not as relevant for B2C searches) is the editorial extreme, with 52.6% of its fashion citations concentrated in its top four sources, and Vogue alone anchoring the number one slot.11 The same Vogue feature that wins Claude's #1 slot can simultaneously win ChatGPT's. Earned editorial coverage has unusually high cross-engine yield. This is great news for fashion brands and retailers, as it is an area they are traditionally used to handling.
Visual search platforms matter more than text-only marketers expect. Pinterest sits in the top three for both Gemini (9.8%) and Perplexity (12.2%) on fashion queries. Instagram appears in the top five for both.12 Visual-search platforms are absent from Claude entirely. Image-first content strategy pays back differently on different engines.
Grok's fashion profile is dominated by social platforms. X.com (28.4%), Instagram (16.5%), TikTok (12.2%), and YouTube (7.4%) together account for 64.5% of Grok's fashion citations. Reddit drives Perplexity at 14.5% and appears in three different LLM top-fives for fashion. For a category that has historically treated Reddit and X as marginal, this matters.
The headline implication paints a complex picture. Sources more traditionally owned or managed by fashion houses are important: editorial coverage they pay for or earn, and visual platforms they post to. At the same time, the fashion citation graph is also dominated by sources fashion brands have traditionally treated as secondary: social discussion they monitor reactively, and reviews they sometimes wish did not exist. Both halves of that mix are what AI engines weight most heavily when deciding what to say about a brand.
Why UGC over-indexes, and why that should worry fashion brands
If you read the citation data closely, a specific signal recurs across almost every model. User-generated content (UGC) — the reviews, forum threads, comment sections, video walkthroughs, and transcripts that customers create — is dramatically over-represented in fashion answers compared to its share of the open web.
There is a clean technical reason for this. Large language models are trained to predict the next token, not to verify facts. When they are asked to recommend or describe a fashion product, they are vulnerable to hallucination: confident assertions that turn out to be wrong. To reduce that risk, modern retrieval-augmented systems lean on sources that exhibit three properties: recency, specificity, and first-person grounding. UGC delivers all three. A 2024 Trustpilot review of a Zara dress includes the wearer's height, the actual size purchased, the way the fabric behaved after a wash, and a verdict, all in a few sentences. That signal is unusually rich and unusually current. It is exactly the kind of evidence a model reaches for when the alternative is making something up.
Editorial coverage from Vogue, GQ, or Highsnobiety plays a related role. It offers expert framing the model can paraphrase without inventing facts. Social platforms add breadth: millions of micro-opinions the model can aggregate. Customer-generated content, editorials, forums, and social posts together form the lattice that LLMs lean on whenever a shopper asks a fashion question. The brand's own website is, by the model's logic, the least trustworthy of all sources, because it has the strongest motivation to mislead.
This is the strategic problem fashion and luxury brands now face. Editorial PR is a discipline most fashion brands manage extremely well. A century of practice has refined it. Brand narrative is a craft they have perfected. The user review ecosystem is the part of the conversation many fashion brands, particularly in luxury, have historically been least comfortable with. Some treat reviews as a customer service inbox to be managed defensively. Others ignore them. A few luxury houses still operate on the assumption that the absence of reviews is itself a form of brand control.
The data says otherwise. In an AI-mediated discovery world, the brands that ignore the review layer are not preserving exclusivity. They are surrendering their AI visibility to whoever happens to be writing about them, in whatever tone, with whatever degree of accuracy. The off-site narrative is being written either way. The only question is whether the brand has a hand on the pen.
That raises a question worth answering with data rather than instinct. What are fashion consumers actually saying when they write reviews, and what does that mean for how AI describes our brands?
What customers actually say
a. The overall picture
Across the full fashion industry, Size and Fit is the single most discussed topic in customer reviews. It is also the most negative. Size and Fit attracts 30% of all reviews. 60% of those reviews are negative.
The wider pattern matters too. Quality and Construction is the second-largest topic at 25% of reviews, again skewed 60% negative. Fabric and Materials is the third, where positive and negative sentiment run close to even. Style and Design is the brightest spot in the conversation: 83% of reviews on style are positive. Customer Service and Returns generates relatively few reviews in absolute terms, but the ones it generates are overwhelmingly negative, particularly in luxury, where it dominates the negative discourse.
The structure is segment-specific. Mass-market consumers complain immediately and most loudly about fit. Luxury consumers complain months later about quality, materials, and after-sales recourse. Different segments fail in different ways, but a single thread runs through both: when product reality diverges from product expectation, the customer writes a review, and that review becomes part of what AI tells the next shopper. The Measmerize study is, in effect, a transcription of the off-site narrative LLMs are reading right now.
b. The data, by segment and category
Each table below is reproduced from the Measmerize 60,000-review dataset. Cells are the share of all reviews within that table's scope that fall into the given macro-topic and sentiment combination. The Total column shows the combined topic share, irrespective of sentiment — the metric most directly readable as "how much of the off-site narrative is about this topic." Each table sums to 100% across all positive and negative cells. Tables are grouped from broadest (fashion industry overall) to most specific (mass-market by sub-category).
Table 4. Fashion industry overall
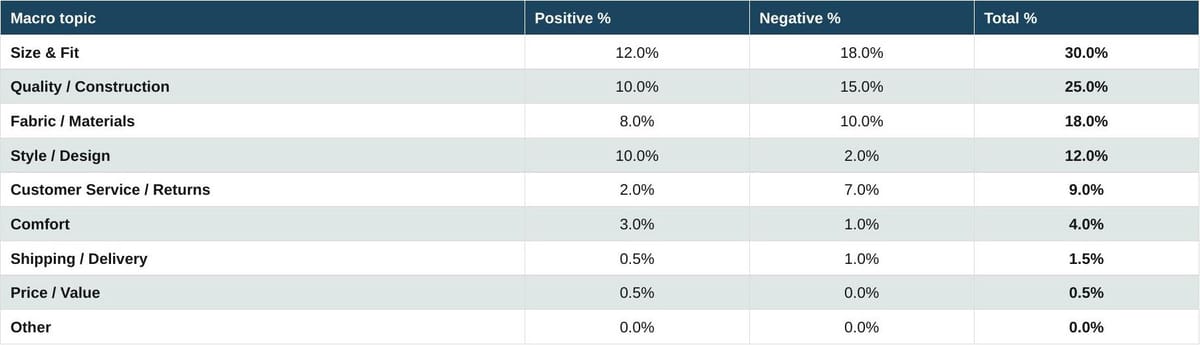 Source: Measmerize 60,000-review study, May 2026.
Source: Measmerize 60,000-review study, May 2026.
Two findings drive the interpretation. Size and Fit accounts for 30% of all conversation when positive and negative are combined, and tilts heavily negative. Quality and Construction sits behind it at 25%. The industry's biggest reservoir of positive sentiment, Style and Design at 83% positive, is concentrated in exactly the area brands are best at marketing. The biggest reservoir of negative sentiment is concentrated in operational and product-fit failures. For AEO purposes, this means LLMs are systematically picking up positive style signals and negative operational signals when they describe a fashion brand.
Table 5. Fashion industry: Apparel
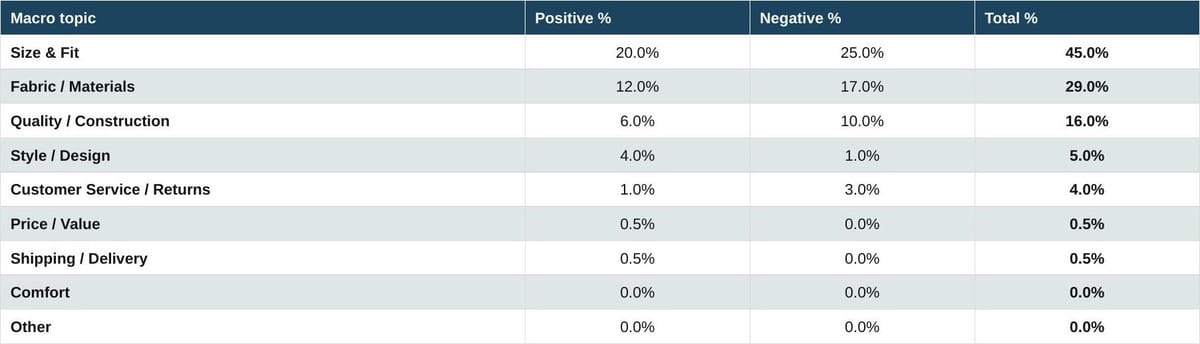 Source: Measmerize 60,000-review study, May 2026.
Source: Measmerize 60,000-review study, May 2026.
In apparel, the imbalance is starker. Size and Fit alone accounts for 45% of all apparel reviews. Fabric and Materials follows at 29%. The single most actionable AEO insight in this paper is hiding in this table. Nearly half of every apparel conversation that LLMs are reading is about sizing, and the negative-to-positive ratio is 25 to 20. A brand that reduces its share of negative fit reviews by even a few percentage points moves the AI narrative materially.
Table 6. Fashion industry: Shoes
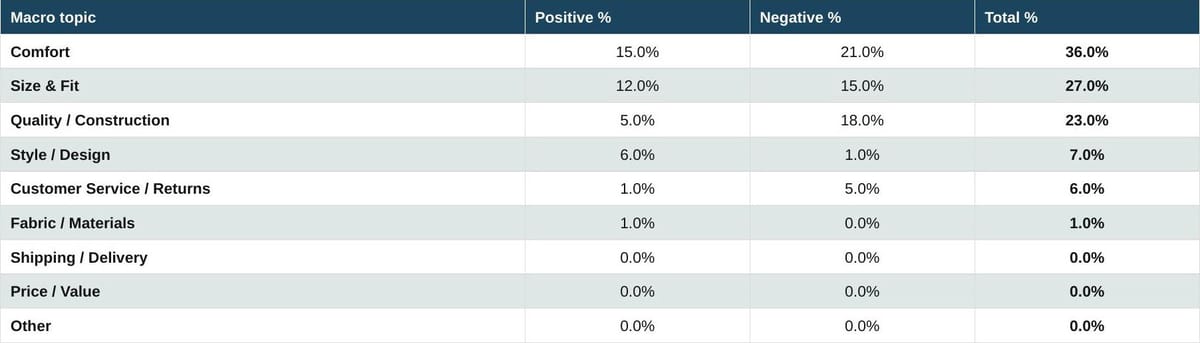 Source: Measmerize 60,000-review study, May 2026.
Source: Measmerize 60,000-review study, May 2026.
Footwear shifts the conversation toward Comfort, which is 36% of all shoe reviews, with a heavy negative tilt thanks to a recurring pattern of blisters, breaking-in problems, and gait-related complaints. Quality and Construction shows the worst positive-to-negative ratio of any topic in any category, at 5% positive to 18% negative. The brands most penalised here are those whose shoes physically fail in the first few months of wear: detached soles, cracked midsoles, broken zippers. Size and Fit remains a top-three issue, though smaller than in apparel.
Table 7. Fashion industry: Bags
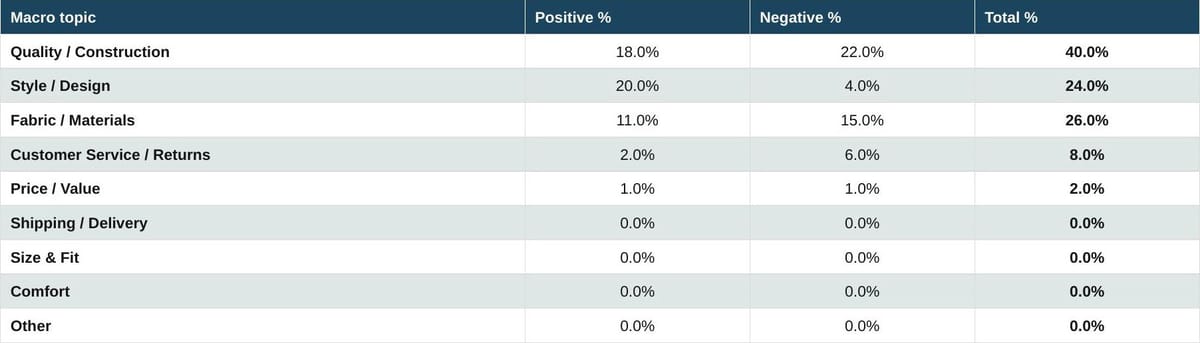 Source: Measmerize 60,000-review study, May 2026.
Source: Measmerize 60,000-review study, May 2026.
Bags reverse the pattern. Size and Fit effectively disappears (a bag does not need to be tried on). Style and Design dominates positive sentiment at 20%, by far the highest positive concentration of any category-topic combination. Quality and Construction dominates the conversation overall at 40% combined, with materials a close second. The LLM narrative about a fashion brand's bag line is, in practice, a narrative about whether the construction holds up. For luxury houses whose handbags are their most-discussed product class, this finding is consequential.
Table 8. Fashion industry: Other (accessories, eyewear, jewelry)
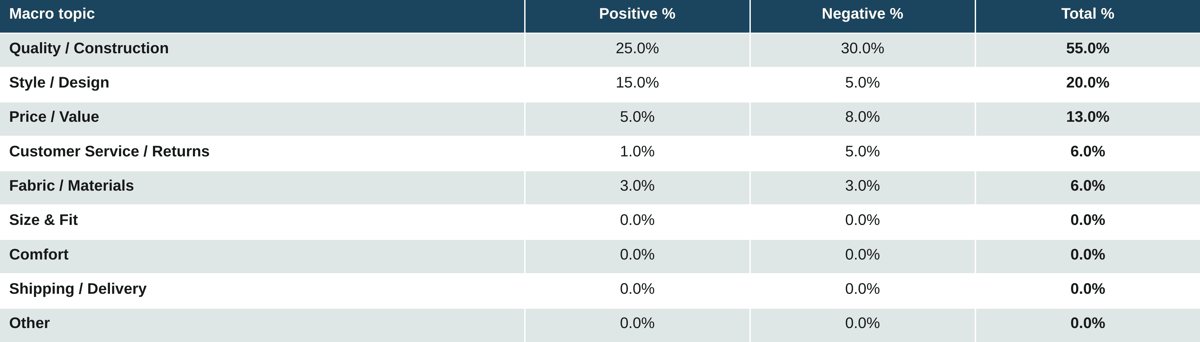 Source: Measmerize 60,000-review study, May 2026.
Source: Measmerize 60,000-review study, May 2026.
Accessories and small leather goods follow the bags pattern, with Quality and Construction the dominant conversation at 55% combined. Style is the second-largest topic and the most positive. Price and Value enters the conversation here in a way it does not for apparel or footwear, with consumers more openly questioning whether the price matches the perceived craftsmanship.
Table 9. Luxury overall
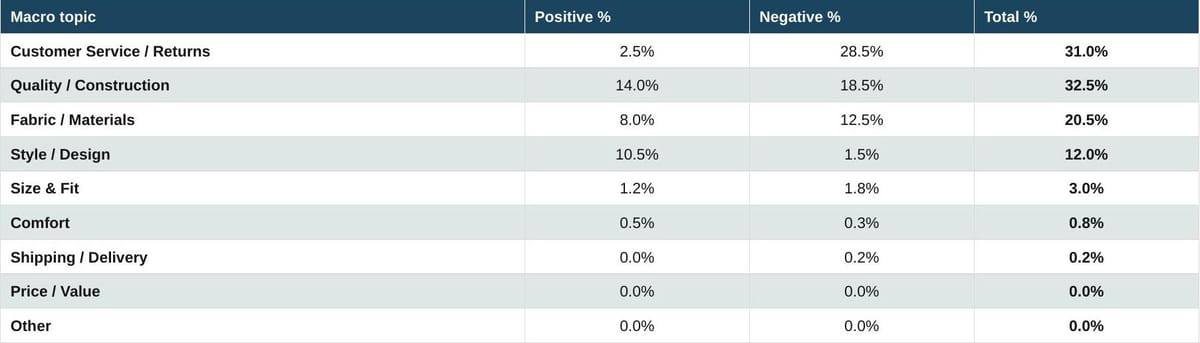 Source: Measmerize 60,000-review study, May 2026.
Source: Measmerize 60,000-review study, May 2026.
The luxury profile is unmistakable. Customer Service and Returns is the dominant topic at 31% of all luxury reviews combined. 28.5% of all luxury reviews are negative on this single dimension. That is not a small flaw. It is the loudest signal the off-site narrative carries about the luxury segment. Quality and Construction follows. Style and Design is the most positive topic, but Style positivity does not offset Customer Service negativity in the volume that LLMs see. Crucially, Size and Fit barely registers. Luxury reviews are not about fit, because fit complaints are resolved in-store rather than written online.
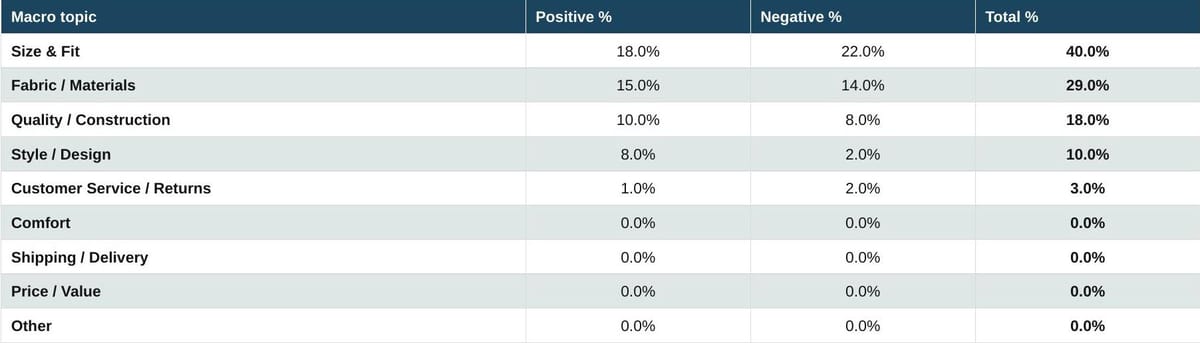
Table 10. Luxury: Apparel
 Source: Measmerize 60,000-review study, May 2026.
Source: Measmerize 60,000-review study, May 2026.
Where luxury apparel does generate online reviews, Size and Fit re-emerges as the top topic at 40% combined, close to the mass-market pattern. The reviews that do exist for luxury apparel are, in effect, written by the same online shoppers who write mass-market reviews, with the same priorities. Fabric and Materials carries the second-largest topic share, weighted slightly more positively than in mass-market apparel: luxury fabric quality does come through in the conversation when consumers like it.
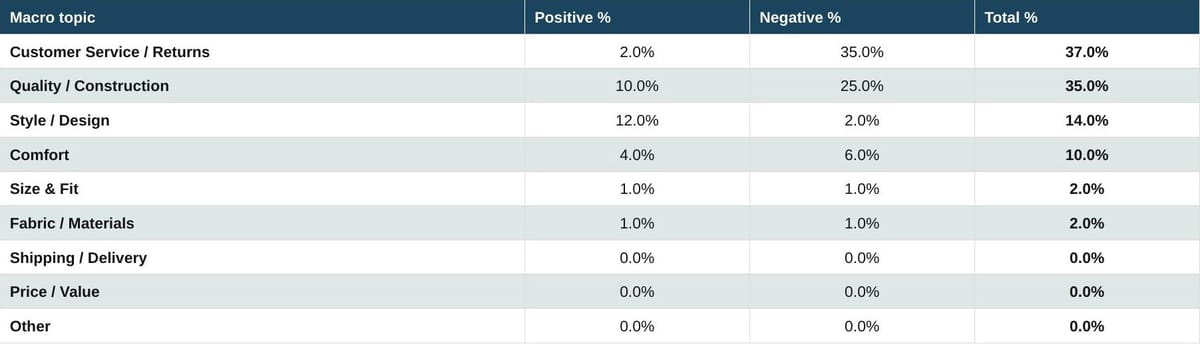
Table 11. Luxury: Shoes
 Source: Measmerize 60,000-review study, May 2026.
Source: Measmerize 60,000-review study, May 2026.
Luxury footwear shows the worst positive-to-negative ratio anywhere in the dataset. Customer Service and Returns is 35% negative and 2% positive, a ratio of 17.5 to 1. The driver is striking and largely procedural: customers who try expensive shoes at home and then attempt to return them are frequently rejected by the brand on the basis of minor scuffs or marks. Quality and Construction layers another 25% negative on top, with sole detachment, finish wear, and hardware issues all surfacing. The 70/30 negative-to-positive split here is the most damaging single finding for the luxury segment.
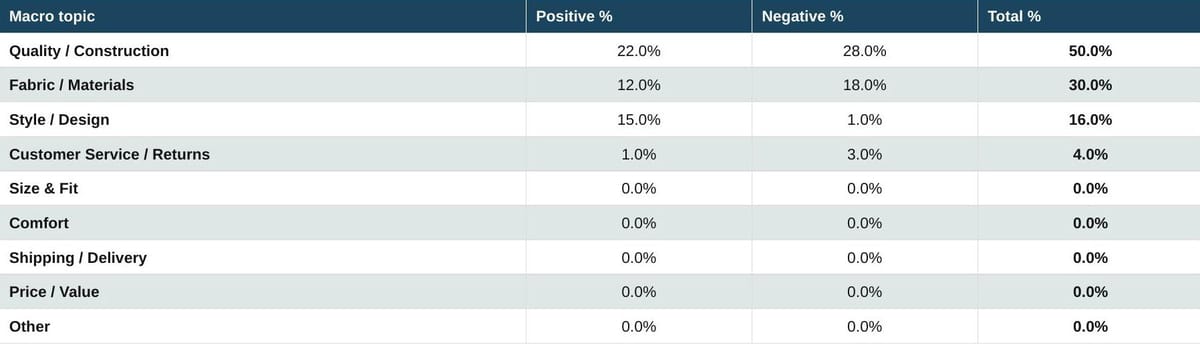
Table 12. Luxury: Bags
 Source: Measmerize 60,000-review study, May 2026.
Source: Measmerize 60,000-review study, May 2026.
Luxury handbags are a quality and materials conversation almost end to end: Quality and Construction at 50% combined, Fabric and Materials at 30% combined. Style and Design generates an unusually clean positive signal at 15% positive against 1% negative. The negative narrative for luxury handbags concentrates on stitching, hardware, finish, and material longevity. These are exactly the dimensions the luxury price premium is meant to underwrite.
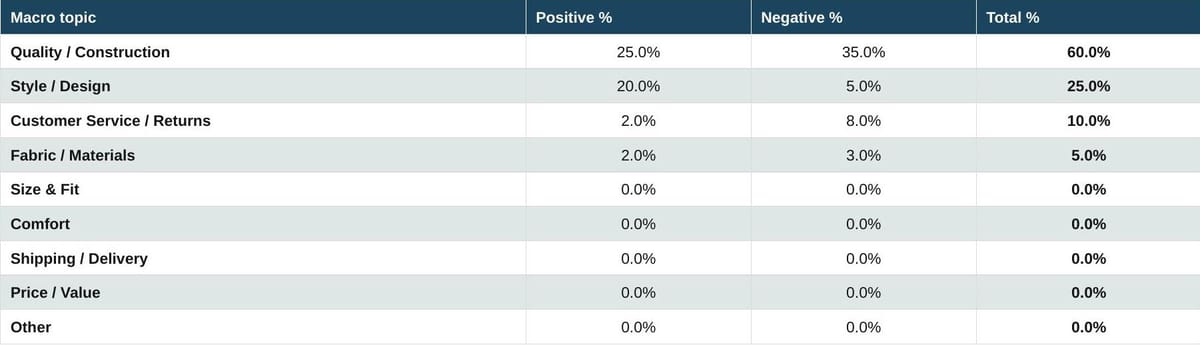
Table 13. Luxury: Other
 Source: Measmerize 60,000-review study, May 2026.
Source: Measmerize 60,000-review study, May 2026.
Luxury small leather goods and accessories follow a similar pattern. Quality and Construction at 60% combined, with the negative tilt sharper than in bags. Customer Service negativity is comparatively modest here, but Quality concerns dominate.
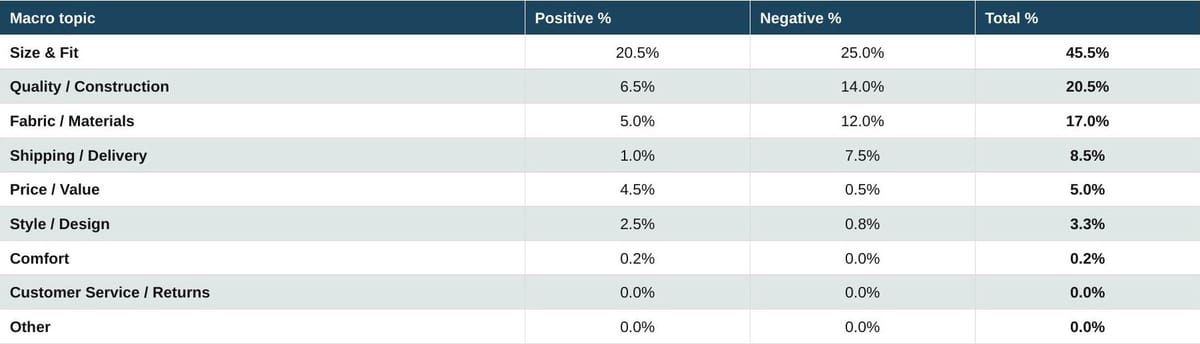
Table 14. Mass market and fast fashion overall
 Source: Measmerize 60,000-review study, May 2026.
Source: Measmerize 60,000-review study, May 2026.
Mass market is, in one number, a Size and Fit conversation: 45.5% of all reviews touch the topic. Negative outweighs positive 25 to 20.5. Quality and Materials follow as the second tier of complaint, with a roughly 2-to-1 negative skew on each. Mass-market consumers also report shipping and fulfilment friction at meaningful volume (7.5% negative on delivery). The cheerful counterweight is Price and Value at 4.5% positive against just 0.5% negative. Value perception is overwhelmingly positive across the segment, which is the durable competitive moat of fast fashion.
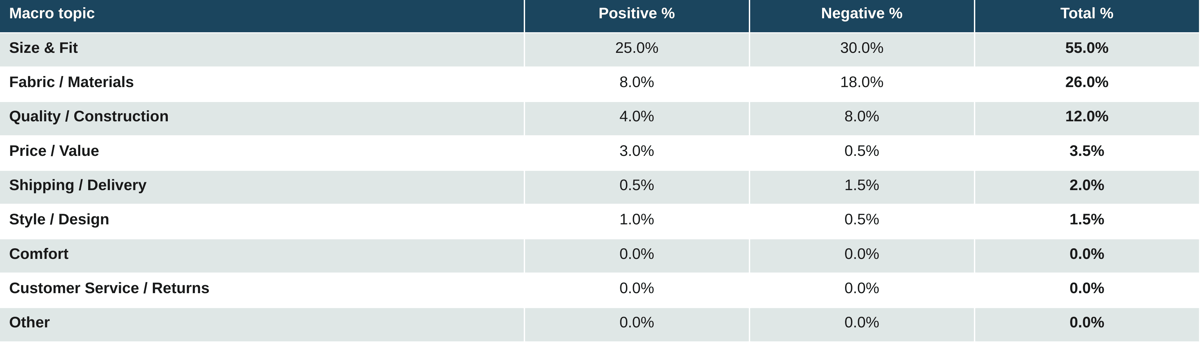
Table 15. Mass market and fast fashion: Apparel
 Source: Measmerize 60,000-review study, May 2026.
Source: Measmerize 60,000-review study, May 2026.
Mass-market apparel is the headline finding distilled to its purest form. 55% of all reviews touch Size and Fit. 30% are negative on it. This is the single largest negative topic concentration in the entire study. The dataset includes multiple explicit confirmations of the underlying mechanism: two pairs of the same garment with the same tag fitting entirely differently, items received four to eight inches off the published sizing chart.13 The fit problem is not a perception issue. It is a manufacturing-control issue with a digital amplifier.
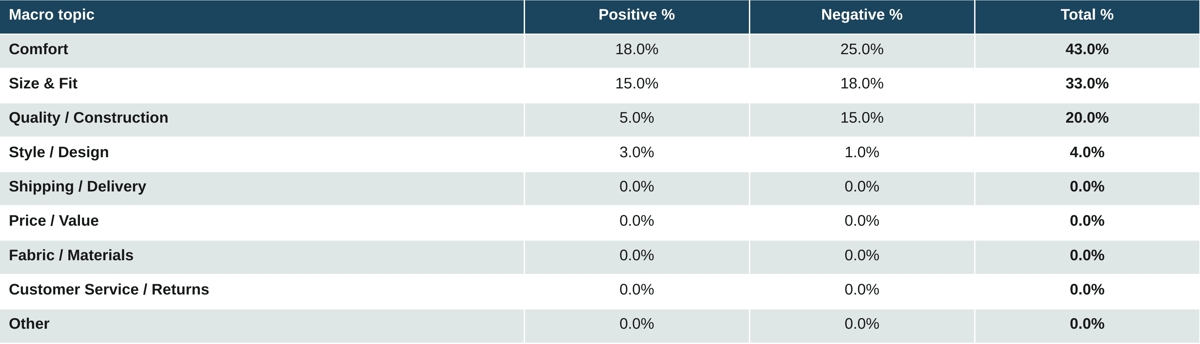
Table 16. Mass market and fast fashion: Shoes
 Source: Measmerize 60,000-review study, May 2026.
Mass-market footwear concentrates the conversation on Comfort (43% combined) and Size and Fit (33% combined). Quality is one-third smaller in volume but heavily negative-skewed at 5 to 15. The recurring complaints are blistering, soles detaching, and shoes that look smaller or larger than the size on the box.
Source: Measmerize 60,000-review study, May 2026.
Mass-market footwear concentrates the conversation on Comfort (43% combined) and Size and Fit (33% combined). Quality is one-third smaller in volume but heavily negative-skewed at 5 to 15. The recurring complaints are blistering, soles detaching, and shoes that look smaller or larger than the size on the box.
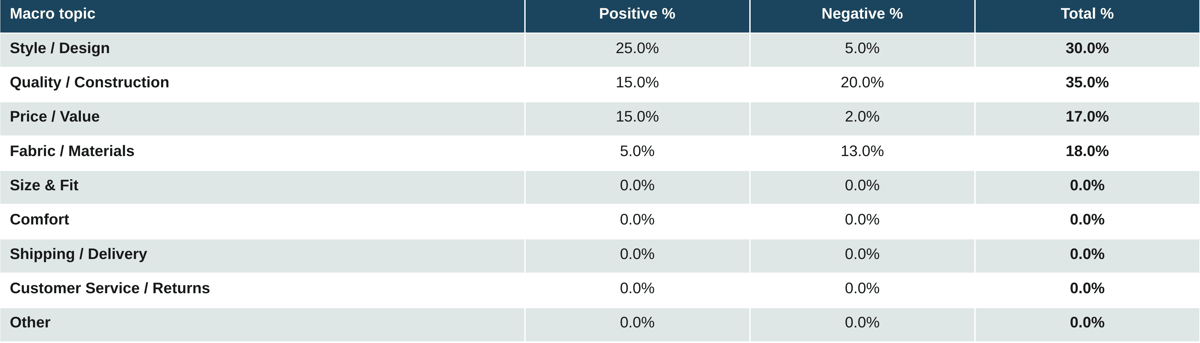
Table 17. Mass market and fast fashion: Bags
 Source: Measmerize 60,000-review study, May 2026.
Source: Measmerize 60,000-review study, May 2026.
Mass-market bags have an unusually positive overall profile. Style and Design at 25% positive against 5% negative, Price and Value at 15% positive against 2% negative. The downside, predictably, is Quality and Construction (35% combined, negative-skewed) and Fabric (5 to 13). The trade is well understood by the consumer: pay less, get the look, accept the wear.
Table 18. Mass market and fast fashion: Other
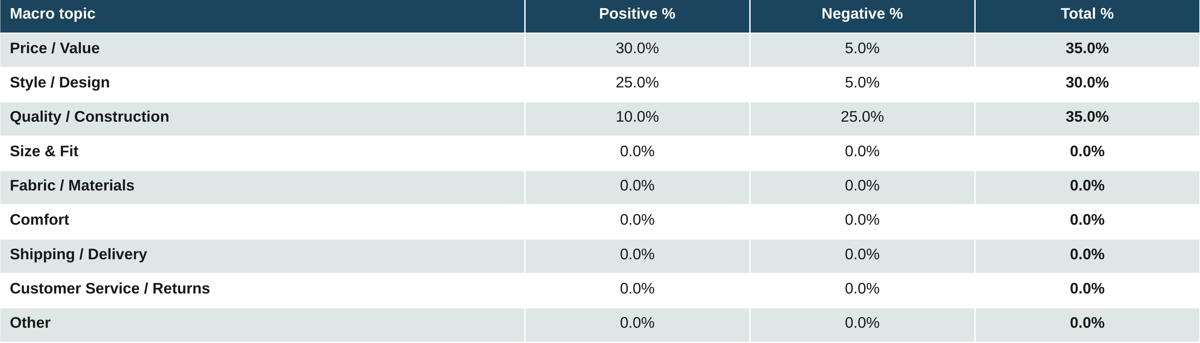 Source: Measmerize 60,000-review study, May 2026.
Source: Measmerize 60,000-review study, May 2026.
Mass-market accessories invert the luxury pattern. Price and Value is the dominant topic at 35% combined, and overwhelmingly positive. Style is similarly positive. The negative sentiment that does exist concentrates on Quality and Construction. The off-site narrative for mass-market accessories is, in effect, a value-for-money endorsement with a craftsmanship caveat.
What does all of this mean for AEO?
Pull back from the individual tables and a clear hierarchy emerges. In mass-market and fast fashion, Size and Fit is the single largest off-site signal LLMs are picking up, and it is overwhelmingly negative. In luxury, Customer Service and Returns is the single largest negative signal, with Quality and Construction layered behind it. Style and Design is the industry's universal source of positive narrative, but it does not offset the operational drag in the segments where operations are visibly broken.
A practical translation: the brands most exposed to AEO downside are those whose reviews concentrate negative volume in topics LLMs treat as factual (sizing inaccuracy, durability failures, painful returns process). The brands most exposed to AEO upside are those who can shift the off-site conversation by solving the underlying problem, particularly sizing, where the friction is solvable with technology.
Recommendations: what fashion and luxury brands should do now
The data points everywhere, but it points hardest at one place. Size and Fit is the largest, loudest, and most negative driver of conversation across the entire industry. It is the single biggest off-site signal LLMs are receiving about fashion brands today. It is also, fortunately, the most solvable. Four priorities follow from the findings.
Priority 1. Solve the fit problem at the source
Roughly 45% of all apparel reviews discuss Size and Fit; 25% of all apparel reviews are explicitly negative on it. Every one of those reviews is feeding the AI model that recommends, or fails to recommend, your product to the next shopper. A brand that reduces its share of negative fit reviews by even five percentage points changes the AI narrative materially.
Four interventions move the needle, and they reinforce each other when deployed together.
AI Size Advisor: personalised recommendation at the point of choice
A size advisor takes a few inputs from the shopper (height, weight, body shape preferences) and returns a SKU-specific size recommendation calibrated against the brand's actual fit data. The Measmerize AI Size Advisor does this in real time on the product detail page. Brands deploying size advisors typically see a step-change in conversion (shoppers who would otherwise abandon out of fit uncertainty complete the purchase) and a measurable drop in return rates driven by wrong-size returns. Critically, fewer wrong-size returns produce fewer angry reviews, and those negative reviews are the off-site signal LLMs are reading.
AI Body Scanner: precise body measurement via mobile
Body shape is the missing input that size charts cannot fix. Two consumers with identical heights and weights routinely take different sizes in the same brand. The Measmerize AI Body Scanner uses a standard smartphone camera to produce a body measurement profile in under 30 seconds, then feeds that profile into size recommendations across the brand's catalogue. The scanner is most valuable for premium and luxury brands whose fits are more cut-specific and whose shoppers are most penalised when the size is wrong.
Accurate brand-specific size charts
Surprisingly few brands publish size charts that match the garments they ship, relying on brand-level size charts. Industry-standard size charts are the lowest-cost intervention with the highest immediate return: clean up the chart, calibrate against the garment, publish per-style variations where they exist. The Measmerize Smart Size Charts product industrialises this, pulling actual garment measurements from production data and serving them dynamically on the product page, converted as body measurements (easier for the consumer to use). For mass-market brands whose 30% negative-on-fit ratio sits at the heart of the AEO problem, this is the table-stakes fix.
Virtual Try-On: launching July 2026
Sizing alone does not tell the shopper whether a garment will drape and proportion the way they hope. Virtual try-on closes that loop by rendering the garment on a body model derived from the shopper's own measurements. The Measmerize Virtual Try-On capability launches in July 2026, designed for total look (apparel + footwear + accessories). The combination of size recommendation, body scan, accurate charts, and virtual try-on covers the full decision path, and shifts the share of fit-related complaints reaching the off-site graph downward across every node.
Priority 2. Make quality and craftsmanship visible
In luxury footwear, Quality and Construction draws 25% negative sentiment. In luxury handbags, Quality dominates the conversation at 50% of all reviews. These complaints land hardest precisely because they undermine the price premium. The solution is partly product (the underlying make has to hold up) and partly representation.
On the representation side, three on-page interventions help. Richer materials documentation on the product detail page (provenance, grade, treatment, expected ageing characteristics) gives both consumers and LLMs more substance to work with. 3D product views allow the shopper to inspect stitching, hardware, and finish before purchase, which reduces the gap between expectation and reality. Brand-owned editorial content that explains the construction (atelier walkthroughs, master craftsperson interviews, materials sourcing detail) gives editorial publications and LLMs alike a higher-quality source to draw on. A brand that publishes 5,000 words on the construction of a handbag is a brand that has armed Vogue, Highsnobiety, Claude, and ChatGPT with the language they need to defend its price.
Priority 3. Streamline the returns experience
Customer Service and Returns is the worst-scoring topic across luxury. 35% of luxury footwear reviews are negative on returns; only 2% are positive. That is by far the worst ratio in the dataset. The qualitative driver is unusually clear: customers who try expensive shoes at home find them rejected on return because of minor scuffs on the sole. The policy is rational from a brand-protection standpoint. It is also generating a 17.5-to-1 negative narrative on the platforms LLMs are quoting.
Three practical adjustments help. First, broaden the exchange policy so that customers with a fit problem can swap rather than return. Fit-driven returns disappear when fit-driven exchanges are easy. Second, calibrate the rejection threshold for return-condition checks so that ordinary at-home trial does not trigger a refused refund. Third, fund a digital concierge layer (chat or video) that can handle disputes before they migrate to Trustpilot. The right combination of these three reduces the volume of negative review velocity directly.
Sizing technology helps here too. 65–80% of returns are influenced by sizing. Replacing consumer guesses with recommendations cuts the volume of returns before the rejection logic ever fires.
Priority 4. Own the conversation across the off-site graph
The brands losing AEO are losing it because narratives run rampant about them on YouTube, Reddit, X, and TikTok without any brand input. This is particularly acute in luxury, where many brands still under-invest in community management on the platforms that drive the most fashion citations on Grok and Perplexity. The four-part remediation is straightforward in principle and difficult in execution. Expand digital community coverage from Instagram and TikTok to also include YouTube, Reddit, and X. The cost is incremental; the AEO return is disproportionate. Monitor conversations in real time using AI-assisted listening tools that can track brand mentions in AI search and flag emerging narratives across all five major LLM citation surfaces. Reply, comment, and explain — not defensively, but to provide accurate information and context the model can later pick up. Earn editorial coverage that engines like Claude and ChatGPT weight heavily; a single well-placed Vogue feature has outsized AEO yield.
None of this replaces the underlying product. It does ensure that when the product is right, the conversation about it lands inside the systems doing the recommending.
How to go further
Get the full brand-by-brand analysis
This white paper presents the aggregate findings of the Measmerize 60,000-review study. The full dataset includes a detailed brand-by-brand breakdown of all 60 brands, covering topic distribution, sentiment ratios, sub-category performance, and notable qualitative drivers for each. The brand-level analysis is available as a gated download for senior leaders at fashion and luxury brands.
Want to see our brand-by-brand breakdown of consumer reviews?
Speak with the Measmerize team
For CMOs, Chief Digital Officers, Digital Directors, and eCommerce leads who want to understand how these patterns apply specifically to their brand and category, the Measmerize team offers a confidential strategy session. We bring the brand-specific review analysis to the conversation, walk through what AI engines are currently saying about your brand, and translate that into a prioritised roadmap covering size recommendation, body scanning, size chart governance, virtual try-on, and off-site narrative management.
Contact us to arrange a session.
About Measmerize
Measmerize is a fashion technology company specialising in sizing intelligence, fit solutions, and AI-powered tools for fashion and luxury brands. Our product suite includes the AI Size Advisor, AI Body Scanner, Smart Size Charts, and Virtual Try-On (launching July 2026). We work with leading mass-market, premium, and luxury brands across Europe, North America, and Asia-Pacific to reduce fit-related returns, lift conversion, and improve AI visibility through better off-site signal.
Learn more at www.measmerize.com.
Appendix: The Measmerize study — how the dataset was built
To map the off-site UGC layer with precision, Measmerize ran a proprietary review-mining study designed to be representative across the full fashion and luxury spectrum. The methodology was built to avoid the two failure modes that distort most large-scale review analyses: volume bias toward mass-market brands, and topic bias toward whichever issues happened to dominate the loudest brands' inboxes.
How was the dataset built?
The starting corpus exceeded two million public reviews drawn from authenticated platforms.14 Primary sources included Trustpilot, the Better Business Bureau, multi-brand retailer portals such as Nordstrom and Shopbop, and transcribed consumer video reviews where product-level sentiment was explicitly detailed. Collection prioritised verified-purchase protocols and high text density over numerical-only ratings.
Raw review volume is wildly uneven across the industry. ASOS alone has more than 191,000 reviews on Trustpilot. Zara has more than 21,000.15 Several luxury houses register fewer than a thousand. A naive aggregate analysis would have produced a survey of what ASOS and Shein customers think, with everyone else as statistical noise.
To prevent that distortion, Measmerize applied equal sampling. 1,000 reviews were drawn from each of 60 brands, producing a curated dataset of 60,000 reviews. The 60 brands span mass-market, mid-market, premium, and luxury categories: 30 luxury houses (from Louis Vuitton and Hermès to Bottega Veneta, Loewe, and Coach) and 30 mass-market and fast-fashion retailers (from Zara, Shein, and ASOS to Lululemon, Uniqlo, and Steve Madden). Equal sampling treats Hermès and H&M as equally important data points, which is the only way to surface segment-specific patterns rather than recapitulating the size of each brand's customer base.
How were the topics identified?
Topics were not pre-defined. They were extracted from the review text itself through a two-pass clustering process. Pass one breaks each review into sentence-level signals (phrases like "sole detached after three months," "runs two sizes small," or "exquisite leather"). Pass two aggregates those signals using semantic similarity, collapsing different phrasings of the same underlying issue into single macro-clusters. For example, "leather peeling," "finish wearing off," and "surface flaking" all converge onto Fabric / Materials.
The resulting taxonomy was then locked across the global dataset to prevent brand-specific distortion. Any signal failing to reach a 3% global threshold was assimilated into the Other category. The final taxonomy has nine macro topics.
Table 19. The Measmerize topic taxonomy
 Source: Measmerize 60,000-review study, May 2026.
Source: Measmerize 60,000-review study, May 2026.
Sentiment was scored per-topic, not per-review. A customer who loved the style but hated the fit is recorded as positive on Style / Design and negative on Size & Fit. Within each table, the cells represent the share of all reviews in that table's scope falling into a specific macro-topic and sentiment combination. Each table sums to 100% of the in-scope reviews. The added Total column shows the combined share of conversation each topic captures.
Footnotes
Footnotes
-
BCG Global Consumer Radar Survey, February 2025. Consumer panel across the US, UK, Germany, France, Japan, China, India, and Brazil; n = 3,819 (overall) and n = 643 (GenAI shopping users). ↩
-
BCG analysis of Similarweb traffic data, year ending Q1 2026. Retailer sample across France, Germany, Italy, the UK, Spain, and Sweden. Fashion and sport: Adidas, Decathlon, H&M, Hugo Boss, JD Sports, Lululemon, Mango, Zalando, Zara. Luxury: Burberry, Dior, Gucci, Louis Vuitton, Pandora, Yoox. Specialty retail: Douglas.de, Elgiganten, IKEA, MediaMarkt, Stadium. ↩
-
AI Overviews citation overlap with Google top-10 organic results: Ahrefs Brand Radar and BrightEdge AI Overviews citation audits, 2026. ↩
-
Gemini holiday-cycle citation audit: Ahrefs Brand Radar, Q4 2025; share of citations to direct retailer domains versus non-retailer sources. ↩
-
BCG Global Consumer Radar Survey, February 2025. Consumer panel across the US, UK, Germany, France, Japan, China, India, and Brazil; n = 3,819 (overall) and n = 643 (GenAI shopping users). ↩ ↩2
-
Keyword research conducted via the Semrush US database (May 2026): related-keyword and question-keyword reports for the core AEO, GEO, AI search visibility, fashion ecommerce, size-and-fit, and virtual try-on clusters. ↩
-
Ahrefs. ↩
-
Ahrefs, BrightEdge. ↩
-
Measmerize synthesis of public 2026 LLM citation benchmarks: Similarweb, Tinuiti/Profound Q1 2026, Peec AI (30M-citation analysis), Overthink Group, Omniscient/Peec BOFU study, BrightEdge retailer analysis, Goodie/Higoodie 5.7M-citation study, Ahrefs Brand Radar (≈250M prompts/month), Semrush AI Visibility Index, LLMpulse Top Cited Domains, SE Ranking Gemini 3 analysis, Conductor 2026 AEO/GEO Benchmarks, ALMCorp/Peec AI 30M-source study, Semrush 13-week study. ↩
-
Industry reporting on the Reddit–OpenAI licensing dispute, Q4 2025: Reddit citations on ChatGPT throttled following commercial-terms changes; Reddit citation share remained structurally elevated on Perplexity and Claude. ↩
-
Editorial concentration metrics derived from Peec AI and ALMCorp 30M-source citation studies, 2026: share of fashion citations captured by Vogue, GQ, Business of Fashion, WWD, Highsnobiety, The Cut, and equivalent tier-one editorial domains. ↩
-
Pinterest and Instagram citation shares: SE Ranking Gemini 3 analysis and Peec AI Q1 2026 fashion-query benchmark. ↩
-
Verified-purchase Trustpilot consumer reviews, retrieved March–April 2026; quotes are reproduced verbatim from the public review text. ↩
-
Measmerize proprietary review corpus, May 2026: 2,041,832 public reviews collected from Trustpilot, the Better Business Bureau, retailer portals (Nordstrom, Shopbop, Net-a-Porter, Mytheresa, Farfetch), and transcribed consumer video reviews. Equal-sampled to 60,000 reviews across 60 brands (1,000 per brand). ↩
-
Public review counts retrieved from Trustpilot.com brand pages, May 2026. ASOS: 191,420 reviews; Zara: 21,108 reviews (figures as displayed at time of access). ↩